Building a Pararius web scraper with Node

Pararius is the biggest Rental home platform in the Netherlands. Almost every rental agent is active on Pararius.
They also have some good bot protection in place. Every time you open a random pararius.com website you will see a Fairlane bot protection page.

So, in this post we are going to try and build a web scraper in Node that is able to get around this bot protection.
Setting up the project
First we are going to create an empty Node project.
mkdir pararius-scraper
cd pararius-scraper
npm initThen, we are going to install the puppeteer dependency. This allows us to control a real Chrome browser from Node.
npm i puppeteerLet's create an `index.js` file. Right now it's just some boilerplate that calls the `start()` function.
const puppeteer = require('puppeteer')
async function start() {
console.log("Start");
// TODO start the browser here.
}
start()
.catch(e => console.error(e))Let's run the program and see if everything works so far.
node index.js
StartThere is a start message, so everything works as expected.
Creating the Browser
Now we are going to create a real browser and load the Pararius website.
async function start() {
const browser = await puppeteer.launch()
const page = await browser.newPage();
await page.goto("https://www.pararius.com/apartments/amsterdam")
// Wait for 5 seconds to let everything load
await page.waitForTimeout(5000)
// Write the result to the result.png file
await page.screenshot({ path: './result.png', fullPage: true })
}This script will start the browser, go to Pararius, wait a bit for everything to load and then write the result to a screenshot.png file.
When opening the screenshot you can see that the Browser fails the Pararius bot check however.

Beating the Bot protection
There is a puppeteer extra stealth plugin that makes the browser look the same as a real normal browser.
Let's install this package and try again.
npm i puppeteer-extra puppeteer-extra-plugin-stealthWe have to make a few adjustments to the require statements to use the extra stealth version of puppeteer.
const puppeteer = require('puppeteer-extra')
const StealthPlugin = require('puppeteer-extra-plugin-stealth')
puppeteer.use(StealthPlugin())However, after running it again, it still shows the bot protection page.
Hmm, even with the stealth plugin we still get the bot check page.
Using a headful browser
Maybe Pararius has found a way to detect headless browsers. We can start the browser in headful mode, which will open a browser window just as with normal users.
To do this we can simply add the headless: false parameter to the launch script.
const browser = await puppeteer.launch({ headless: false })And after running this we now pass the bot check page, and are able to view Pararius homes.
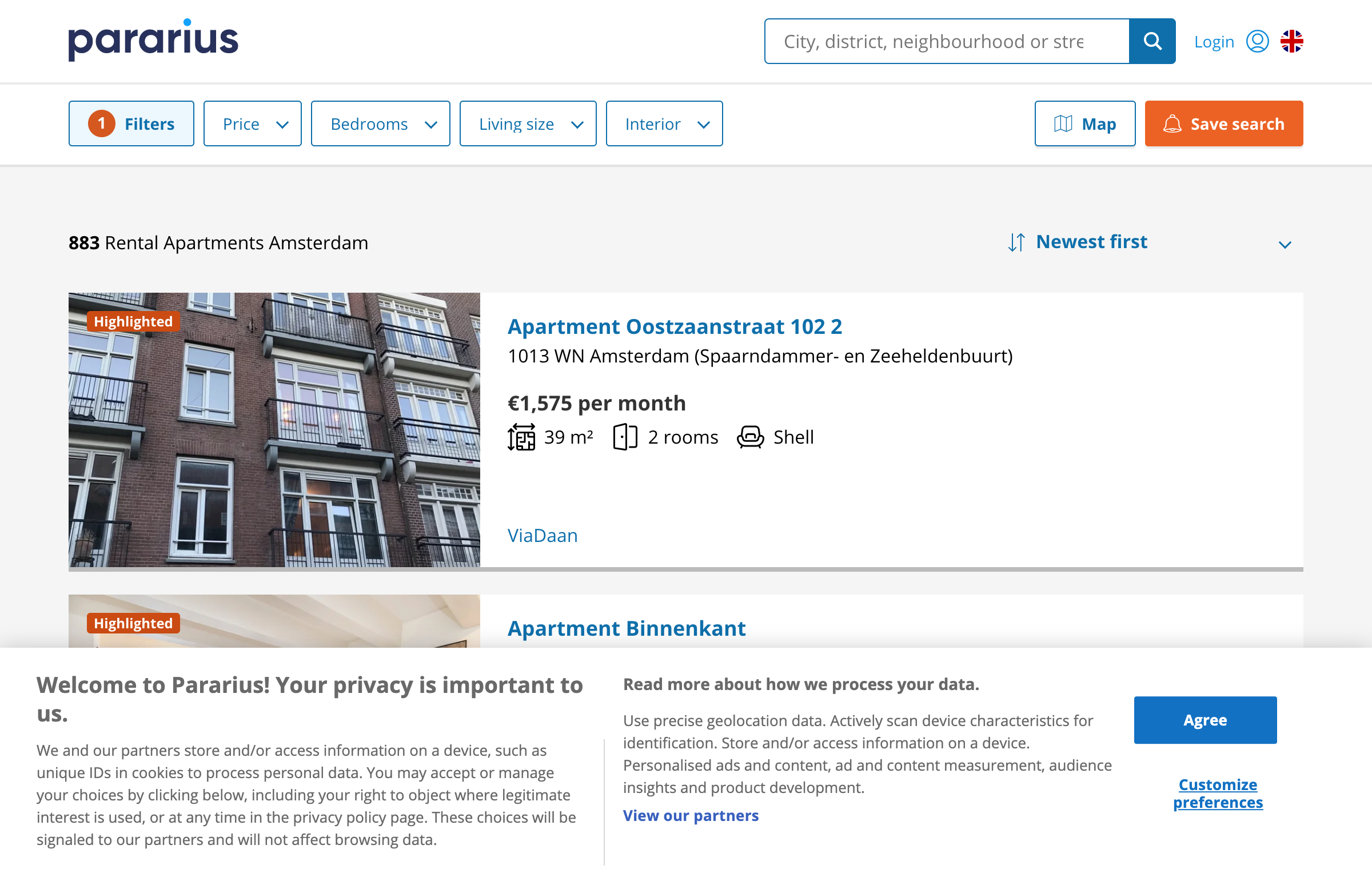
Scraping the house addresses
Let's write a simple scraper that gets all house addresses on the page. To this we are going
to use the page.$$ method that will return all elements of a given CSS selector.
To check what CSS selector we need I right-click in the Pararius browser and click "inspect".
Then I can hover over a house address to see that I need the selector .listing-search-item__title
// Get all house address elements.
const elements = await page.$$(".listing-search-item__title")
const addresses = [];
// For each of the addresses get the TextContent and put the result in an array
for (const element of elements) {
const address = await page.evaluate(el => el.textContent, element)
addresses.push(address)
}
// Print out the array of addresses
console.dir({ addresses })Let's run this and see if it outputs an array of addresses.
node index.js
{
addresses: [
'\n' +
' \n' +
' \n' +
' House Utrechtsedwarsstraat 78\n' +
'\n' +
' \n' +
' ',
and so on...It does seem to return the addresses, but with a lot of whitespace and newlines.
We can clean this up by using the trim() function.
addresses.push(address.trim())And when running it again we get a nice list of addresses.
node index.js
{
addresses: [
'Apartment Cannenburg',
'House Utrechtsedwarsstraat 78',
'House Erich Salomonstraat',
'Apartment Jan van Schaffelaarplantsoen',
'Apartment IJburglaan 595',
]
}How to run this on a server
If we were to try and run this program on a server we would get an error from Chrome.
This is because Chrome will try to create a Browser window, but to do that it needs a graphical output i.e. a display. And of course, servers don't have a display.
You could try to setup a virtual frame buffer such as Xvfb. This will create a "virtual screen" that allows Chrome to paint the browser window on a server.
But setting this up is quite tricky, and requires a lot of resources.
Proxy servers
Another problem is that if you were to scrape Pararius a lot then eventually they will block your IP address.
To circumvent this you will need to connect to a proxy network with Puppeteer so that you get a new IP address on each request.
Conclusion
We've created a simple scraper that scrapes Pararius addresses.
We were able to circumvent the bot detection by starting headful browsers.
Feel free to extend this basic project to scrape a lot more data from Pararius.
Happy coding 👨💻
Ready to begin?
Start now with 500 free API credits, no creditcard required.
Try Scraperbox for free